ปัญหาข้อมูลไม่สมดุล (Imbalanced Data in Classification Model)

ในการสร้างโมเดลเพื่อจำแนกข้อมูลในกลุ่มของวิธี Classification เพื่อจำแนกว่าข้อมูลที่ทำนายได้ว่าจะเป็นค่าใดนั้น สัดส่วนของคลาสแต่ละคลาสในชุดข้อมูลเรียนรู้ (Training Set) เป็นสิ่งสำคัญที่อาจส่งผลต่อการทำนายของโมเดล ซึ่งในปัจจุบันพบว่าปัญหาข้อมูลไม่สมดุล (Imbalanced Data) เป็นปัญหาที่หลายธุรกิจมักจะพบเจออยู่บ่อย ๆ ซึ่งเกิดจากปริมาณข้อมูลที่มีไม่เพียงพอต่อการนำมาวิเคราะห์ และหากอยากได้ข้อมูลที่สมดุลกัน ธุรกิจนั้นอาจจะต้องใช้เวลามากในการรอที่จะเก็บข้อมูลจนมีความสมดุล หรือบางครั้งอาจจะแทบเป็นไปไม่ได้เลยที่ข้อมูลจะมีความสมดุลด้วยตัวเอง ซึ่งในโลกแห่งความเป็นจริงระยะเวลาในการตัดสินใจขับเคลื่อนธุรกิจด้วยข้อมูล (Data Driven Organization) เป็นสิ่งสำคัญต่อการดำเนินธุรกิจเป็นอย่างมาก เพื่อจะลดระยะเวลาการเก็บข้อมูลจึงจำเป็นต้องหาวิธีแก้ปัญหาดังกล่าว
ซึ่งหนึ่งในสิ่งที่สำคัญเป็นอย่างมากที่วิศวกรข้อมูล (Data Engineer) ไม่สามารถละเลยได้นั่นคือลักษณะและคุณภาพของข้อมูลก่อนจะนำเข้าโมเดล โดยข้อมูลที่นำมาใช้อาจจะเป็นข้อมูลดิบ (Raw Data) ที่จัดเก็บอยู่บน Data Lake, Data Warehouse หรือ ระบบฐานข้อมูลของธุรกิจนั้นก็ได้
Imbalanced Data คืออะไร?
ถ้ายกตัวอย่างให้เข้าใจได้ง่าย ๆ สมมติว่า มีข้อมูลเรียนรู้จำนวน 10 รายการ โดยมีการระบุตัวแปรเป้าหมาย (Target Label) ให้ 2 ค่า ได้แก่ แอปเปิ้ล และกล้วย ซึ่งสามารถนับจำนวนตามกลุ่มได้เป็น 1) แอปเปิ้ล 3 รายการ และ 2) กล้วย 7 รายการ
จากจำนวนข้อมูลแอปเปิ้ลและกล้วยในชุดข้อมูลดังกล่าว จะพบว่าข้อมูลเกิดความไม่สมดุลกันเนื่องจากมีกล้วยมากกว่าแอปเปิ้ล โดยมากกว่าเป็น 2 เท่า ดังนั้น หากนำชุดข้อมูลทดสอบ (ที่สมมติว่าเรารู้ว่ามันคือแอปเปิ้ล) มาทำนายเพื่อจำแนกข้อมูล เป็นไปได้ว่าผลลัพธ์อาจจะมีความโน้มเอียงไปทำนายว่าเป็นกล้วยมากกว่าได้ ดังตัวอย่างตามภาพด้านล่าง ซึ่งนั่นหมายความว่าโมเดลนี้ทำได้ไม่แม่นยำนัก อันเกิดจากการความไม่สมดุลของข้อมูลเรียนรู้ จึงทำให้โมเดลมีความโน้มเอียงในการทำนายไปยังกล้วยมากกว่าจะเป็นแอปเปิ้ล
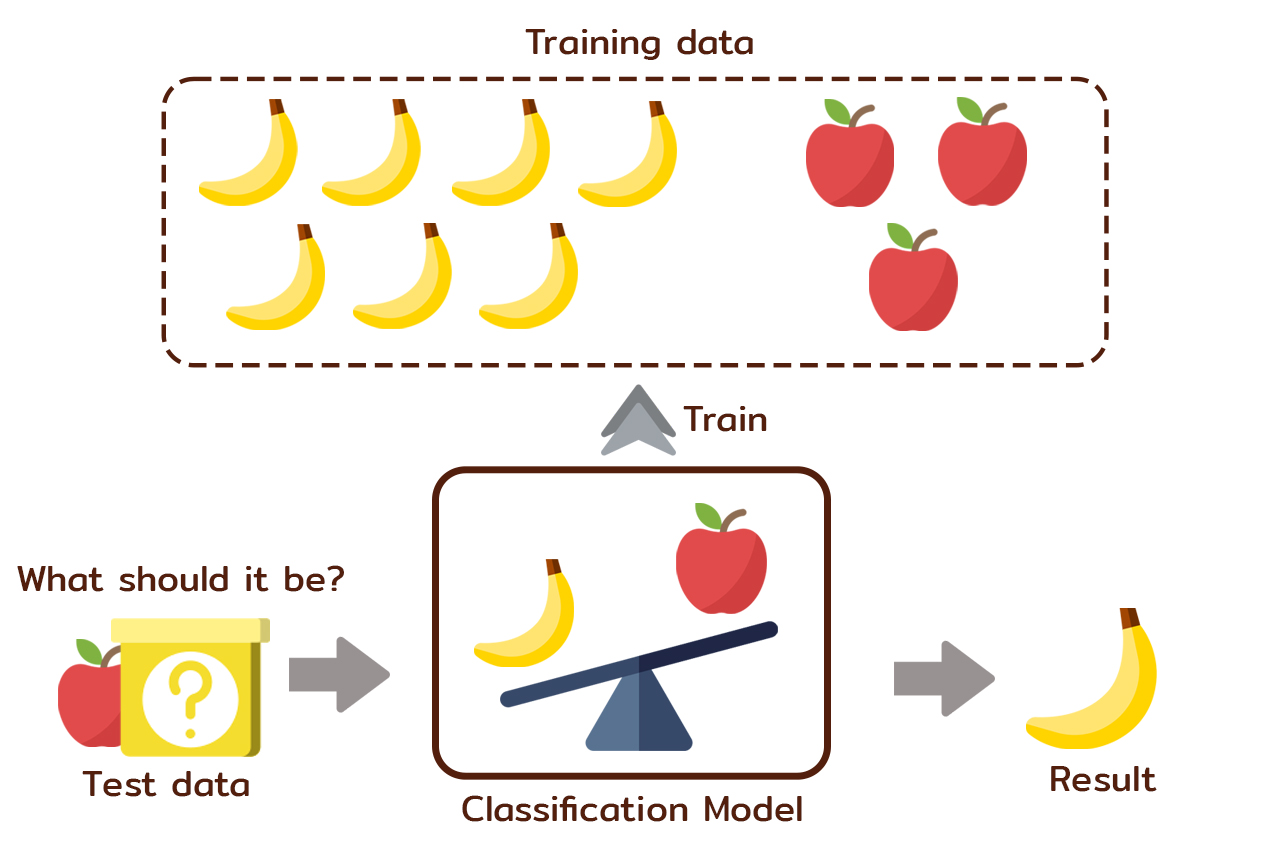
จากปัญหาความไม่สมดุลของข้อมูลนี้ จึงจะต้องผ่านกระบวนการเตรียมข้อมูล (Data Preparation) เพื่อที่จะแก้ปัญหาดังกล่าว และทำให้ได้ชุดข้อมูลที่มีสัดส่วนที่เท่ากันหรือใกล้เคียงกัน เพื่อป้องกันการทำนายที่โน้มเอียงไปยังคลาสใดคลาสหนึ่ง (Prediction Bias) และทำให้ผลลัพธ์ของโมเดลการทำนายมีประสิทธิภาพที่ดียิ่งขึ้น
วิธีแก้ปัญหาข้อมูลไม่สมดุล
การแก้ปัญหาข้อมูลไม่สมดุล มีวิธีแก้ปัญหาด้วยกันหลายระดับ ได้แก่ ระดับข้อมูล (Data Level) และระดับอัลกอริทึม (Algorithm Level) โดยในบทความนี้จะพูดถึงวิธีแก้ไขในระดับข้อมูล ซึ่งเป็นวิธีที่นิยมใช้กันมากที่สุด
วิธีการแก้ปัญหาข้อมูลไม่สมดุลแบบหลายคลาสในระดับข้อมูล เป็นวิธีที่ทำให้ข้อมูลในคลาสขนาดใหญ่ (Majority Class) และคลาสขนาดเล็ก (Minority Class) มีขนาดเท่ากันหรือใกล้เคียงกันโดยการสุ่ม (Sampling) สามารถแบ่งกลุ่มการแก้ปัญหาข้อมูลไม่สมดุลได้เป็น 3 วิธี ดังนี้
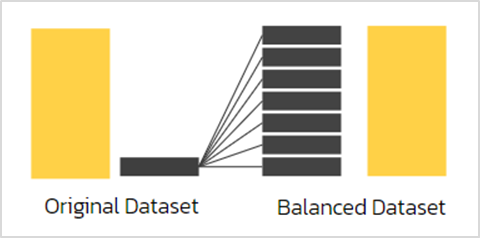
1. การสุ่มเพิ่มข้อมูล (Over-Sampling)
การสุ่มเพิ่มข้อมูล เป็นวิธีการสุ่มเพื่อเพิ่มข้อมูลในคลาสขนาดเล็ก ให้มีขนาดใกล้เคียงหรือเท่ากับคลาสขนาดใหญ่ ได้แก่
- RandomOverSampler: ROS วิธีนี้เป็นการเพิ่มข้อมูลในคลาสขนาดเล็กโดยใช้การสุ่มจากชุดข้อมูลเดิม ซึ่งจะต้องระวังเรื่องปัญหาการซ้ำซ้อนของข้อมูลที่เกิดจากการสุ่มซ้ำ ซึ่งจะส่งผลให้โมเดลเกิดการ Overfitting ได้
- Synthetic Minority Oversampling Technique: SMOTE วิธีนี้เป็นการเพิ่มข้อมูลในคลาสขนาดเล็กโดยสังเคราะห์ข้อมูลใหม่จากชุดข้อมูลเดิม ทำให้ข้อมูลในคลาสขนาดเล็กมีการกระจายตัวที่ดีขึ้น และช่วยให้ค่าความสำคัญของข้อมูลไม่สูญหาย ซึ่งจะช่วยลดปัญหาการเกิด Overfitting ได้
หมายเหตุ: Overfitting หมายถึง การที่ได้ผลลัพธ์ในการเทรนโมเดลที่ดีมากกับชุดข้อมูลเรียนรู้ (Training Set) แต่เมื่อทำไปใช้งานจริงในข้อมูลที่ไม่เคยผ่านการเรียนรู้ (Test Set) พบว่าผลการทำนายของโมเดลได้ผลลัพธ์ไม่ดีเท่าเดิม
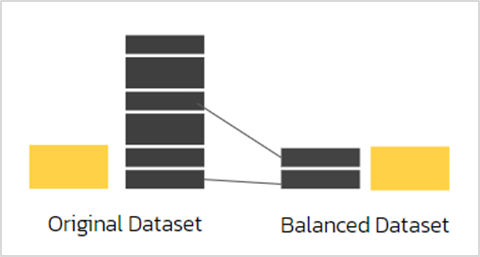
2. การสุ่มลดข้อมูล (Under-Sampling)
การสุ่มลดข้อมูล (Under-Sampling) เป็นวิธีการสุ่มเพื่อลดข้อมูลในคลาสขนาดใหญ่ ให้มีขนาดใกล้เคียงหรือเท่ากับคลาสขนาดเล็ก ได้แก่
- Tomek’s Links: T-Links วิธีนี้ใช้การจับคู่ของข้อมูลต่างคลาสที่อยู่ใกล้กัน แล้วเลือกลบข้อมูลคลาสขนาดใหญ่ออก เพื่อให้เกิดช่องว่างระหว่างกลุ่มขึ้น ทำให้ข้อมูลมีความกระจายตัวที่ดีและช่วยให้การแบ่งกลุ่มข้อมูลมีความชัดเจนมากขึ้น
3. การสุ่มแบบผสม (Mixed-Sampling)
การสุ่มแบบผสม (Mixed-Sampling) เป็นวิธีการสุ่มข้อมูล โดยใช้เทคนิคการสุ่มลดข้อมูลและสุ่มเพิ่มข้อมูลร่วมกัน เพื่อทำให้ข้อมูลในแต่ละคลาสมีความใกล้เคียงหรือเท่ากัน ได้แก่
- SMOTETomek ซึ่งเป็นเทคนิคผสมระหว่างการสุ่มเพิ่มข้อมูลด้วยวิธี SMOTE และการสุ่มลดข้อมูลด้วยวิธี Tomek’s Link โดยจะทำการสุ่มเพิ่มข้อมูลด้วยเทคนิค SMOTE ในคลาสขนาดเล็กเพื่อให้แต่ละคลาสมีขนาดเท่ากันก่อน แล้วจึงจะสุ่มลดข้อมูลโดยใช้เทคนิค Tomek’s Link ต่อไป เพื่อทำให้ข้อมูลมีการแบ่งกลุ่มที่ดีขึ้น

ศึกษาเพิ่มเติมเรื่องการแก้ปัญหาข้อมูลไม่ดุล
สามารถดูวิธีแก้ปัญหาข้อมูลไม่สมดุลแบบอื่นเพิ่มเติมได้ที่ https://imbalanced-learn.org/stable/user_guide.html
ศึกษาเพิ่มเติมเรื่องเทคนิคการทำนาย Classification
สามารถดูเทคนิคแบบอื่นเพิ่มเติมได้ที่ https://scikit-learn.org/stable/supervised_learning.html
บทสรุป
การสุ่มข้อมูลเป็นวิธีหนึ่งที่จะช่วยลดระยะเวลาในการเก็บข้อมูล และเป็นหนึ่งในวิธีการเตรียมข้อมูลให้ข้อมูลมีความสมดุล ไม่เกิดปัญหาข้อมูลไม่สมดุล หรือ Imbalanced Data in Classification ก่อนนำไปเข้าโมเดล ทั้งนี้ เมื่อได้ชุดข้อมูลที่มีความสมดุลกันในแต่ละคลาสแล้ว และหากนำไปเทรนโมเดลแล้วพบว่าประสิทธิภาพที่ได้ยังไม่เป็นที่น่าพึงพอใจนัก อาจจะต้องร่วมกับการแก้ปัญหาด้วยวิธีอื่น ๆ เพื่อช่วยปรับปรุงโมเดล (Model Tuning) ให้มีประสิทธิภาพที่ดีขึ้นต่อไป

by
Rukchanok Piyapanichayakul
Data Engineer


